Why we built Restate
Posted August 24, 2023 by Stephan Ewen ‐ 26 min read
Hello world, dear friends, developers, and infra software people! Today, we want to share something special with you - the first bits about our new project, Restate. (For the impatient, feel free to skip the intro and jump right to “Enter Restate”.)
Our Journey to Restate
It has been 18 months since Till, Igal, and I wound down our involvement in the Apache Flink community. Creating Flink and making it one of the defining pieces of the real-time data and stream processing space was an incredible honor. And despite the tough times, very fulfilling.
The Restate story started with Flink as well. While building Flink and working with the community of users and customers, we saw all the good parts that worked well, but also all the types of applications, where stream processing and Flink were not the best fit. Some of the harder use cases that were also among the most fascinating ones, were the ones where developers tried to use it for applications other than analytics. Over time, we started to map applications onto a spectrum:

To the left, stream processing (including streaming SQL) is a great match. And for all the challenges it has, it does some things just magically: You write app logic, and it runs in a scalable and resilient way, with strong consistency guarantees.
Distributed transactional applications and more traditional RPC-based applications on the right end of that spectrum are far from that experience. And those are still the default for many use cases that have critical correctness requirements, like user management, logistics, ecommerce, payment, etc.
For those applications, you either stay monolithic, or you end up dealing with a complex web of retries, state machines, distributed locks, synchronizations. You worry about idempotency across services, distributed transactions, conditions of durability, consistency models, or create cron-jobs to collect dangling state as a fail-safe. Let’s not even go into partial network partitions and split-brains. You end up with a major part of your code being about failure-handling and consistency issues. You either invest heavily into infrastructure, or you’ll face tough times in production.

The reason why event-sourcing architectures (using stream processing for general-purpose applications) haven’t taken over everything is that their properties and trade-offs are just not a good match for general transactional applications. Those applications tend to have complex per-event control flow (often dynamic control flow) and many interactions with other services and systems. They don’t run fully asynchronously, because a user might be synchronously waiting for a response. They need strong consistency, not eventual convergence of computed views.
But clearly, the status quo for transactional applications and distributed microservices is not great, and we believe it is possible to improve this. Restate is our take on how to bridge the two worlds: Combining the simplicity and flexibility of generic RPC-based applications, with an event-driven foundation that gives you the scalability and almost magical resilience of stream processing.
We are excited to share some first glance at our work. While we want to add a bit more before we make Restate publicly available (you can request beta access today), we want to give you a first impression of where this is going, and get your feedback. Because how well Restate achieves its goal depends on how well our approach fits with your setups, processes, and mental models.
Enter Restate
Restate’s vision is to make distributed applications and microservices (including transactional applications, workflows, and service orchestration) significantly simpler to build, while simultaneously making them scalable and resilient to all sorts of infrastructure failures. Our approach maintains the simplicity and familiarity of RPC- and event-based APIs and does not ask users to adopt a new programming paradigm.
Restate’s core is a very special lightweight event broker, coming as an open-source, self-contained single binary, written in Rust. It runs on laptops and in the cloud without dependencies.
Restate lets you build applications with what we call durable async/await: you write familiar RPC handlers, and Restate makes them reliable by adding durability to invocations, promises, communication, and state. Restate handles durability and recovery (including recovering partial handler executions) in a way that eliminates much of the typical complexity of distributed applications.
The RPC handlers run in the same way you are used to: as standalone processes, in containers, on Kubernetes, on FaaS (like AWS Lambda). Restate sits as a proxy in-front of and in-between services, similar to a message queue, proxying requests and transporting messages. Conceptually, Restate is an event broker on steroids: it routes messages/invocations, but also tracks their execution, handles retries and recovery, persists partial progress (via a durable execution log), stores state, and manages persistent timers. Restate handles tracing, and runs a query engine for the state.

Restate’s core is a distributed Raft log of events and commands, with indexes, the ability to compute over the log (to actualize commands) and to invoke functions/handlers based on events. We chose this architecture (instead of a library that writes/reads steps to/from a database) for a few reasons:
This specific log-centric architecture massively reduces the amount of distributed coordination that is required in the stack; such coordination is the source of both overhead and operational complexity. That way, Restate actually reduces complexity and doesn’t just shift it into another block in your architecture. We touch on that briefly below, and will dedicate the next post in the series for a detailed discussion on our log-centric approach.
The fact that Restate pushes invocations and state makes it work beautifully with auto-scaling and FaaS setups. Put your endpoint on FaaS, on KNative, or as a Kubernetes deployment with horizontal pod autoscaler (HPA). Scales out of the box.
Let’s look at Restate now from the app-developer’s perspective. The following examples are in TypeScript / Node.js. Restate itself is language-agnostic - we are implementing Restate SDKs in various languages. The TypeScript SDK is the first one we release.
Hello world in Restate!
Here is a simple example of a Restate-based RPC-handler, which counts how many times it has been invoked for a certain name.
const greet = async (ctx: restate.RpcContext, name: string) => {
const seen = (await ctx.get<number>("count")) ?? 0;
ctx.set("count", seen + 1);
return `Hello ${name} for the ${seen + 1}-th time!`;
}
restate
.createServer()
.bindKeyedRouter("greeter", restate.keyedRouter({ greet }))
.listen(8080);
// call this via `curl localhost:9090/greeter/greet --json '{"key": "Restate"}'`
While this is a very simple example, it illustrates the first Restate concept: state and compute go tightly together. We use Restate’s keyed handlers, using the name parameter as the key. Restate will sequentialize invocations per key and allow handlers to attach state to that key (here the seen state). When calling the handler, the previously attached state is supplied through the context, and updates are written back atomically with the completion of the handler. Either the handler completes and the state is updated, or everything is retried with the original state. That way, we cannot have concurrent modifications or double updates/lost updates.
You can think of this as somewhat similar to a transactional stateful actor model, or even a simple version of stream processing. To make these guarantees extend to the complete call round-trip, you can use a Restate promise-based client, rather than making just an HTTP call.
Or, hook this up to a reliable event source that Restate can deduplicate (like Apache Kafka), and you basically have exactly-once stream processing, with the option to run your application code on FaaS. 🤯🤯🤯


More examples of Restate applications are in the Restate examples repository, including workflows (food order processing), consistent APIs (stripe-style payment API), and microservice architectures (e-commerce shop)
Let’s look at a more elaborate example now, and go step by step through how Restate works.
How does it work? Dissecting an example
The code below is from the Ticket Reservation example. It implements a service method that puts a ticket into your cart, if the ticket was successfully reserved, and times out the reservation after 15 mins.
async function addTicketToCart( ctx: restate.RpcContext, userId: string, ticketId: string) {
// try to reserve the ticket
const success = await ctx.rpc(ticketApi).reserve(ticketId);
if (success) {
// update the local state (cart contents)
const tickets = (await ctx.get<string[]>("cart")) ?? [];
tickets.push(ticketId);
ctx.set("cart", tickets);
// schedule expiry timer
ctx.sendDelayed(sessionApi, minutes(15)).expireTicket(userId, ticketId);
}
return success;
}
First of all, note just how little code this is. There is no handling of connection errors, retries, connectivity, idempotency, or other reconciliation of state (between ticketApi, cart, and timers). That’s not because we just dropped this for simplicity, (or because we pretend some library hides this), it is because this isn’t needed - the example is fully resilient to all sorts of failures, in a way that is hard to achieve manually.
This is what Restate is all about: Writing much less code and getting a more robust and scalable implementation of your application.
Let’s unpack this, step by step, to understand what happens between Restate and this function.
As others pointed out before, reliable systems start with a log. So does Restate, but with a different take on what the log needs to do. Restate’s log is Raft-based, but not a classical event log: partition leaders also act on events in the log. To make this efficient (save round-trips), Restate implementes a form of mixed data/command log and additional shuffle capabilities to move events between partitions. A bit like a fusion of a command log and a mini stream processor.
1. Invoking addTicketToCart(...)
Restate persists the invocation event in its internal log, to ensure it is durable for possible retries/recovery. The log is also the place where ordering-by-key happens, to avoid concurrent invocations for the same key.
Restate connects to the service/handler endpoint either through HTTP/2 (streaming) or through a request/response protocol that is designed to support API gateways and FaaS like AWS Lambda. Let’s assume the HTTP/2 (streaming) case here.
2. RPC to ticket service
The RPC to the ticketApi (line 3) creates a message, which contains a description of the RPC: target, and payload. The message is sent through the HTTP/2 connection to Restate, where it is persisted in the log. This is a simple atomic write that fulfills two purposes: (1) It makes the message available to be dispatched to the target (ticketApi) and (2) it records that this point in the function has been reached (the execution journal).
The Restate worker dispatches the message to the ticket service. The response is added to the log as well and streamed back to the addTicketToCart() invocation where it completes the promise.


3. Failure, fencing, retries, replays
Here is where it gets really interesting: Let us assume any type of infrastructure failure happened: The process/container/machine with addTicketToCart() function crashed, the connection broke, a partition happened, or something else that made us wonder if maybe the process is unresponsive.
Restate will re-dispatch the original event to invoke the addTicketToCart() function, possibly to a different process or FaaS invocation. Two more crucial things happen:
- Restate associates internally a new Epoch with the call, which acts as a fencing token against the previous invocation. Even if the previous invocation is still around (was only temporarily partitioned off and re-connects), that one will not be able to add anything to the log anymore. It is fenced off, to prevent zombies from interfering with anything.
- Restate adds the messages created by the previous invocation (like the RPC message), as the previous execution journal to the re-invocation.
The re-invocation then executes the function again and replays the journal in the background. When the RPC method is called, it finds the RPC message already in the previous execution journal and discards this step.
If the RPC response is also in the journal already, the RPC result promise is directly resolved with that result. If the response isn’t there yet, the function awaits the result promise; Restate eventually routes the response to that promise in the new invocation. Effectively, the RPC result promise was recovered in another process.
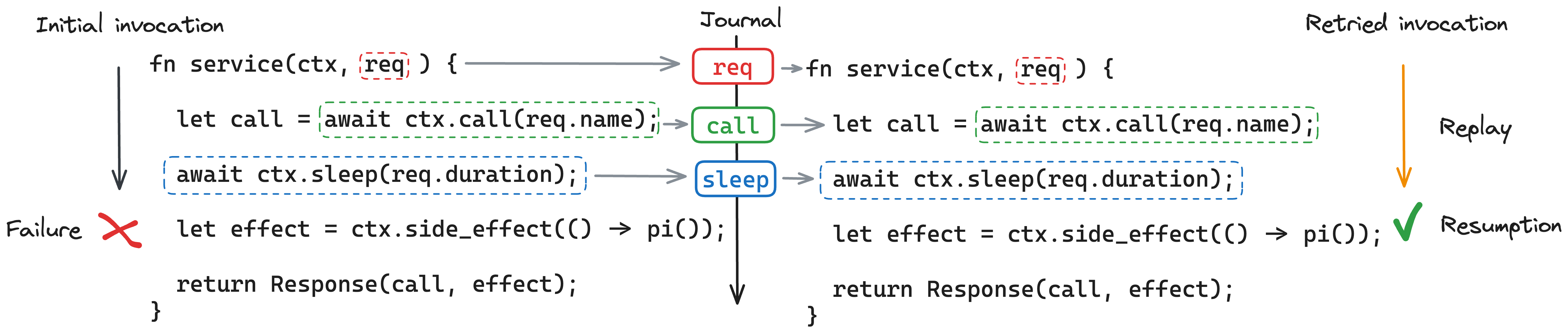
This approach is what is typically called journal-based (or log-based) durable execution. It recovers the partial progress of the function as if nothing ever failed. Restate applies durable execution specifically to distributed promises - we hence call it distributed durable async/await. The main requirement of this approach is that code is deterministic.
Here we need to point out two of the fundamental aspects of Restate’s design:
The log is the ground truth. Everything else is just transient state that follows the log. What does that mean?
a. Let’s assume that the RPC message from the example above was persisted in Restate’s log: Then the re-invocation will already have that message in the execution journal. It will not create another RPC message, but re-create the promise for that message. At the same time, the RPC message is guaranteed to be delivered to the
ticketApi, because it is durable in Restate’s log, which is where messages are dispatched from.b. Let’s assume the message was not in the log when the crash happened. It doesn’t matter where the message was (not created / on the wire / in a buffer). From Restate’s perspective, the RPC didn’t happen. The previous message is guaranteed to not be delivered, and the re-invocation will not find the message in the journal, and consequently create the RPC message as if it was the first time.
A single write here persists both the progress of the computation (whether the function issued the RPC already) and the existence of the effect (the RPC message to be delivered), avoiding the need for any additional coordination (like 2PC). Restate batches message writes to its log through its consensus, to keep the cost per write low.
The same entity is responsible for persisting ground truth and acting on ground truth: the log partition that stores the progress (journals the messages) also acts on them: it delivers messages, updates state indexes, maintains timer indexes, dispatches the invocations, etc. That makes it trivial to keep all related state consistent. Again, no coordination across different partitions or systems is needed.
There is a nuance to this: Not all invocations from a chain of calls are necessarily dispatched from the same log partition: especially when invoking keyed handlers, the dispatching partition is determined from the key. To support that, Restate can move messages between log partitions with exactly-once semantics.
This log-as-the-ground-truth philosophy is really powerful in practice. During development of the TypeScript SDK, we had at some point a bug in the network code, and occasionally lost messages between the app and Restate. It didn’t affect correctness at all - our regression suites still ran successfully. We only noticed at some point that recoveries were happening also in some tests where we didn’t expect them.
4. Suspensions
This architecture enables a nice property: If some response (like to an RPC) takes too long (e.g., more than a few seconds), the service can “suspend”, which means releasing all resources and going away (even stopping the process and/or scaling down the deployment). This works practically the same way as if the service failed at that point - just in a graceful manner. Once the response message is available, the service is re-invoked to resume (like a recovery), with the previously pending Promise now completed.
This is how Restate also efficiently supports FaaS deployments: Functions aggressively suspend whenever they await responses and acknowledgements. No time (and money) spent waiting.
5. Updating the cart and scheduling expiry
The access and update to the cart state work similarly to the previous “Hello World” example. The state update and the scheduled RPC (to expire the reservation) flow back through the HTTP/2 stream, together with the response to the function call.
The function/handler execution doesn’t wait for those messages to be in the log before proceeding - the messages flow asynchronously to the log. This is possible because the sequence of messages is ordered, and because the log is the ground truth: If the function completion with the result value is in the log, we know that all previous messages are in the log as well and their effects processed. If the completion (and possibly other messages) are not in the log after a failure, the recovery resumes exactly from the journal that was found in the log - re-creating exactly those messages that had not been created or hadn’t yet made it to the log.
This pipelining of messages (persisting progress) and execution helps to make durability with Restate much cheaper, compared to an approach where the SDK would make database calls to persist messages/progress.
Beyond
This was a short intro to Restate’s core mechanism. For the sake of not letting this already long section explode further in size, we glossed over some parts. We’ll rectify some of that in the next section, where we explore how all of this works when Restate-based handlers interact with other services and systems. In follow-up blog posts, we will explore how to handle cases where you cannot move forward with execution after recoveries (only roll back), and how to handle cases where callers need to place bounds on the latency of results.
The basic principles on which Restate builds are remarkably simple, but therein lies their power. They are flexible, one can build both simple RPC handlers and complex workflows with them. One can build one self-contained durable task or a mesh or reliably communicating microservices. And at the same time, their simplicity allows for robust implementation of the core (no complex coordination across systems, no multi-writes, distributed transactions, etc.), which is essential: Complex systems must grow from simple principles and building blocks.
Interfacing with other systems
In many setups, you won’t have all services and all parts of your application driven by Restate. In fact, when you are picking up a new system for the first time, you probably have only some isolated pieces using it.
While we plan to go deeper into these topics in the future, the story just wouldn’t be complete without touching on these aspects at least superficially. So let’s look at how to keep some of the guarantees when interacting with other systems.
Awakeables (Persistent Promises) for calls to other systems
When you make an RPC call to a service in Restate, the RPC result promise is persistent and recovered upon failure. That makes the communication between services so seamless, even in the presence of failures.
For external interactions, Restate has a similar primitive, called Awakeable. Think of it as an external version of Restate’s persistent promises. When you call the other system, you pass the URL of the result promise, and the other system completes (resolve/reject) that promise via a simple HTTP call:
curl http://localhost:9090/dev.restate.Awakeables/Resolve --json '{ "id": "ThaomYs19P8Bi3AgY-RThnAAAAAQ", "json_result": "foobar" }'
Completing (resolving or rejecting) the promise is a durable and idempotent operation. Upon completion, any handler that awaits that promise will resume. Because the response URL and the resolution of the Awakeable are durably handled by Restate, async calls to other systems here survive service/process failures and avoid duplicates.

Side effects
Side effects are a convenient way to capture small pieces of code that are non-deterministic or interact with other systems. Side effects are executed once, then their result is captured durably in the log, before it is made available to the application. Upon replay, they are not re-executed, but the durable result is immediately returned.
While side effects may be executed more than once (if a failure happens before they complete or before the result is durable), they guarantee that by the time the result is used, it is durable and deterministic. They are useful for all types of operations that are idempotent (possibly when depending on deterministic parameters) but should not be arbitrarily often re-executed over time.
const idempotencyToken = await ctx.sideEffect(() => uuid.v4());
const payment = await ctx.sideEffect(() => stripeClient.call(idempotencyToken, paymentInfo));
Event streams
Letting Restate ingest events from other logs/queues or writing them to such systems is often possible with exactly-once semantics. For example Kafka’s APIs (and upcoming APIs) make this perfectly doable - the mechanism is the same as in stream processors that integrate with Kafka (like Apache Flink).
Transactionally updating databases
Restate allows developers to attach K/V state to handlers, which is useful in itself. However, distributed services will work with their own databases in most cases: for the purpose of isolation, or because of special capabilities of the database (like vector search, time series, text search, …).
Besides the usual approaches to consistency of database updates, you can use some useful tools from Restate:
- Keyed handlers (like in the “Hello World!” example) let you avoid concurrent access to rows: If your handler is keyed by the same key as the table’s primary key, you have no two operations on the key at the same time.
- Each handler invocation has a durable invocation ID (stable across retries) and an epoch (incrementing with retries) that help you implement versioning or semantic locks.
If you want, you can use side effects to coordinate SQL transactions, for example via PostgreSQL prepared transactions, like in this (simplified) example:
const txnId = restate.random(); // random that is deterministic across recoveries
await restate.sideEffect(() => {
// issue a rollback for this ID in case we prepared the transaction before and just crashed
postgres.rollback_prepared(txnId);
postgres.begin_transaction();
postgres.execute(statement);
postgres.prepare_transaction(txnId);
});
postgres.commit_prepared(txnId);
In this example, Restate becomes the transaction coordinator: Restate’s log stores the commit decision for the database transaction.
CAS updates (DynamoDB) or logical versions (ElasticSearch) can similarly help to connect Restate’s state/decision and the database changes.
So who is Restate for? What are good use cases?
In our mind, Restate is for anyone building backend applications where consistency matters (and where an SDK is available in the language they want to use 🙃). Restate itself is language-agnostic - the first SDK we implemented is Node.js / TypeScript, but more SDKs will come in the next months.
Some use cases we believe Restate excels at are:
Low-latency workflows: Like payments processing, inventory keeping, user management, billing, … Including cases where you probably like consistency, but hadn’t thought of workflows before, due to latency. Like
- between a shopping cart and the product inventory
- for concurrent API endpoints (stripe-style payment API example)
Serverless applications and workflows: create one (or a few) functions with the business logic, instead of a spaghetti of many Lambdas plus StepFunctions.
Microservice orchestration: Writing orchestration functions as simple promise-based code where you previously needed to create complex state machines and handle state transitions durability.
Background tasks, task queues, cron jobs: anytime you need to kick something off to run in the background and to work reliably (run to the end)
- Updating multiple services on a trigger
- Feeding bigger chunks of data through external APIs (link to example coming up)
Event-driven applications: Restate runtime and execution are asynchronous in nature, but the programming model lets you work with simple promises and coroutines, without worrying about failures. The built in K/V state and ability to suspend while waiting rounds this off.
Simple (serverless) stream processing: You can use Restate to transform and enrich streams of events, with exactly-once guarantees.
While Restate is not Apache Flink or Kafka Streams when it comes to sophistication of streaming APIs and throughput, it is much more lightweight. The processes with the stream transformation logic are stateless (no RocksDB or large memory state store), can be easily deployed in a FaaS or autoscaling way (KNative), can be operated like other stateless processes (e.g., rolling upgrades), and can be in different languages.
For simple enrichments and transformations, this makes the pipelines quite easy to build and run.
While we have paid an extraordinary amount of attention to the consistency/resilience aspects (because they end up being the worst causes of complexity and pain), we paid equal attention to give Restate a stellar developer experience.
Even if failure semantics are not first on your mind, you’ll also find Restate’s to help with many useful bit for all sorts of applications:
- Message queuing
- Durable timers
- K/V storage
- Simple bridge to AWS Lambda
- Tracing
- Service Discovery
- Exactly-once Kafka integration (coming up soon)
Beyond reliability and scalability: observability and introspection
After building reliable distributed applications, operating them isn’t trivial either. Restate can help with that as well.
Open Telemetry
Restate dispatches function/handler invocations, but also captures what further invocations are triggered as part of those invocations. That way, Restate has all the information to identify relationships and dependencies between functions, and can generate OpenTelemetry traces for services called through Restate, without any need to use a service mesh or to attach and propagate tags. The only config you need is where to push traces to, like a Jaeger endpoint.
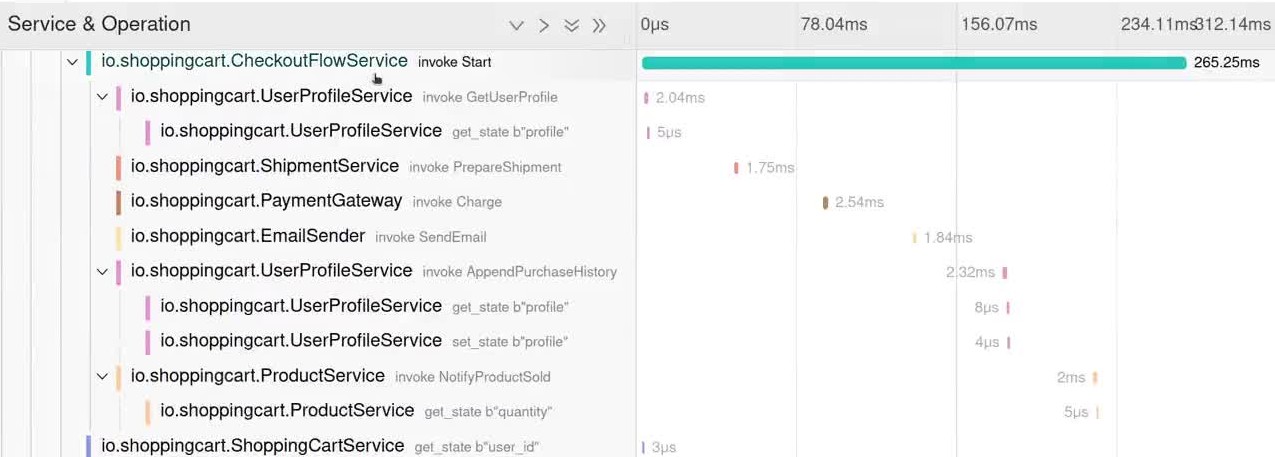
Status and state queries
The Restate log streams events for invocations, state, and other actions between services. We added a simple SQL interface to let users query the current status of services and the events being dispatched. The interface is based on the Arrow Datafusion query engine, runs directly on the internal logs and RocksDB indexes, and exposes itself with a PostgreSQL wire-compatible endpoint.
Here is a sample output, using the psql tool from Postgres, running the following query:
SELECT service, method, id, status, invoked_by_service, invoked_by_id FROM sys_status;
service | method | id | status | invoked_by_service | invoked_by_sid |
---------------------+----------+----------------------------------+-----------+---------------------+----------------------------------+
ShoppingCartService | Checkout | 018a18d17926719987f5a82a887b5d79 | suspended | | |
CheckoutFlowService | Start | 018a18d1793a745ba0ce595b19fea514 | invoked | ShoppingCartService | 018a18d17926719987f5a82a887b5d79 |
The same tool can be used to query state attached to handlers:
SELECT service, service_key_utf8, key, value_utf8
FROM state
WHERE key='cart'
AND service_key_utf8 IN
(SELECT DISTINCT s.service_key_utf8
FROM state s
WHERE s.service='io.shoppingcart.ShoppingCartService'
AND s.key='status'
AND s.value_utf8='"ACTIVE"');
service | service_key_utf8 | key | value_utf8 |
--------------------+--------------------------------------+------+-------------------------------------------------------------- ...
ShoppingCartService | e886a1f8-3010-41cc-808b-c81da7d43241 | cart | {"reservations":[{"productId":"12","priceInCents":1090},{"pro ...
ShoppingCartService | 24ac6429-7b09-4f87-9ccf-4a5506ae7638 | cart | {"reservations":[{"productId":"13","priceInCents":2945},{"pro ...
To avoid confusion: This isn’t a SQL shell across all your distributed data (which typically lives in many distinct databases), but purely for the state attached to Restate handlers (often session state, like in Redis). Very useful nonetheless, full SQL over session state is great for debugging. And if you used stream processing before, imagine having a fast SQL shell over the state stored in your Flink or KStreams state.
Restate is in closed beta
We currently share Restate in a closed beta with interested users. If you would like to get access, please sign up here.
During closed beta, you get access to the binary / Docker image of Restate, plus the npm packages and sources for the Node.js / TypeScript SDK, libraries, examples, and documentation. We plan to open the Rust source code of Restate a bit later when going towards the public release.
The currently shared Restate version implements a single node worker, with a consensus quorum hardwired to be one (meaning it relies on a persistent disk for durability). Beyond that, there is no restriction. We will unlock the replicated/sharded variant in the future; right now, some elements are still under implementation, like config changes and proper catch-up. But you see the consensus log-centric approach in action already when tailing Restate’s logging output.
We are working on an early version of a managed Restate service. Please reach out in case you are interested in that.
What is next?
We hope that the ideas behind Restate got you similarly excited as they excite us. There might be quite a few questions still on your mind after reading this.
There certainly are a lot of thoughts still on our mind after writing this; there is so much more to talk about. We plan to continue sharing those thoughts and questions in future posts:
- Taking a broader look at the type of distributed systems problems and failure scenarios commonly found in applications, and how they shaped Restate’s design
- Restate is a highly asynchronous system. How do we make sure the latencies are practically low enough, and how do we allow users to place bounds on them?
- Latency and overheads, but also improvements (better locality) of Restate’s approach
- Determinism in application code, and how this impacts code upgrades
- Stream processing with Restate
- (I am sure more will come to mind)
If this piqued your interest, try Restate out, give us a follow @restatedev, or join Discord to stay in the loop for updates.
And if this is a space in which you want to build, please let us know! We are looking for experienced systems engineers to join our team!.
Appendix: “Well, isn’t this just like…”
Kafka plus Temporal: Restate is log-based (like Kafka), and in a way, Restate does for long-running RPC-style applications what Kafka did for event-driven applications and streams.
Restate uses durable execution (similar to Temporal) as a part of its toolkit. Restate goes beyond that, in how it efficiently integrates durable execution with persistent promises, consistency of communication, and long-lived state. In a way, Restate generalizes the idea of durability of computation from a workflow mechanism to a distributed services mechanism. See the next question for a few examples of what that means for your application.
It is also worth mentioning that how we capture the partial progress of the computation is orthogonal to the core architecture. We started with journal-based durable execution, because we found it the best way to get started. We could also pick a different approach, like process snapshots, or serializing closures. One could also build an entirely different API on the Restate protocol, that models explicit state machines and uses Restate to atomically commit state transition and effects, and reliably handle the communication with other systems.
A workflow engine with an RPC-handler abstraction? This is one way you can use Restate, as a workflows-as-code system (similar to Azure Durable Functions or Temporal) and probably a really useful one (no JSON, YAML jungle).
But Restate goes beyond typical workflows (and beyond the above-mentioned systems) in several dimensions, for example:
- Restate’s lightweight approach makes it possible to use its workflows in places where it would be infeasible to run a classical workflow, latency and deployment wise.
- Restate doesn’t just handle one RPC handler in a reliable way, it also handles durable and consistent interactions with other services. Between Restate-backed services, but also external interactions: awakeables (persistent promises), message queues, side effects.
- Unlike most workflow engines, the logic runs and deploys the same way as before. Restate doesn’t make you run your code as tasks in workers. This lets you use all the tools you already have for deployment, versioning, testing, etc. Start the process with the code from a debug shell and just place a breakpoint - it is very convenient to work that way.
- Workflows are no longer a special thing. Use durability directly where you need it, rather than factoring that part out into a workflow.
- You can easily keep state across workflow invocations (K/V state) without a database dependency, to carry context forward across executions.
A synchronous RPC abstraction bolted onto a message queue? No, it is not. That is an anti-pattern for two reasons: (1) It hides the asynchrony of message passing behind a synchronous API (2) it mixes the transient nature of RPC with the durable behavior of events/MQs. Restate differs from that in ways that may seem subtle, but make all the difference: (a) the RPC abstraction is promise-based and (b) those promises are persistent across failures across processes, and (c) that allows Restate to suspend the handlers when waiting on those promises.
The result is that the call site that awaits the response (correlated with the request) seamlessly recovers from failures and that the call site doesn’t actually stay up waiting. The last part can be beautifully observed when running a Restate-based handler on AWS Lambda: Whenever a promise awaits an external event (like an RPC response), the Lambda goes away and comes back when the response is there, continuing where it left off. It executes exactly as if you manually wrote an event-driven state machine that runs transitions upon receiving events.
Stateful Functions (in Apache Flink): Our thoughts started a while back, and our early experiments created StateFun. These thoughts and ideas then grew to be much much more now, resulting in Restate. Of course, you can still recognize some of the StateFun roots in Restate.
Is this a 100x platform? Well, probably not. Given how much of software development is understanding the problem and describing the right semantics, reducing the actual development time to 0 would (in most cases) still give you less than 10x speedup.
But Restate is a platform that makes it delightfully easy to implement many types of tasks, and it can speed up development and significantly reduce operational errors. What X that boils down to depends on the use case and person or organization that uses it.
Join the community and help shape Restate!
Join our Discord!